Home » social media
Category Archives: social media
Watching Musk fiddle while Twitter burns
Seeing Elon Musk pledge to reinstate Trump on Twitter understandably starts another wave of folks leaving the platform, but if we all leave Twitter, won’t it just become what Trump dreamed Parler would be?
")
I’ve been on Twitter for more than 15 years, and it’s the platform that has most felt like home for the majority of that time. I’m heartbroken by what Musk has managed to do to the platform and the people who (mostly used to, now) run it in a few short weeks. His flagrant disregard for users or the platform itself is gutting. (I’m with Nancy Baym on what’s being lost here, even if the platform stays online and doesn’t fall over.)
For better or worse, the media broadly (and academia in many ways, to be fair) has used Twitter as a proxy of public opinion. That won’t change overnight. If mostly moderate and left-leaning voices leave, does that give Trump via Musk exactly what he always wanted?
Trump gets Twitter as a pulpit to say whatever half-formed thought escapes his head, and a crowd of MAGA voices to cheer him on at every step. While the echo chamber idea has been widely challenged, it feels like this could be how that chamber would actually cohere.
From outside the US, that anyone, let alone a meaningful percentage, of US citizens believe the Biden election was ‘stolen’ feels like it shows exactly how powerful and destructive the Trump’s Twitter can be.
I don’t want to be putting dollars in Musk’s pocket either as he burns users and employees alike, but I’m deeply conflicted about just leaving the space which still has 15 years of ‘public square’ reputation. I don’t have a solution, but I have many fears.
And, yes, like many I’ve set up on Mastodon to see how that space evolves.
ABC Perth Spotlight forum: how to protect your privacy in an increasingly tech-driven world
 I was pleased to be part of the ABC Perth Radio’s Spotlight Forum on ‘How to Protect Your Privacy in an Increasingly Tech-driven World‘ this morning, hosted by Nadia Mitsopoulos, and also featuring Associate Professor Julia Powles, Kathryn Gledhill-Tucker from Electronic Frontiers Australia and David Yates from Corrs Chambers Westgarth.
I was pleased to be part of the ABC Perth Radio’s Spotlight Forum on ‘How to Protect Your Privacy in an Increasingly Tech-driven World‘ this morning, hosted by Nadia Mitsopoulos, and also featuring Associate Professor Julia Powles, Kathryn Gledhill-Tucker from Electronic Frontiers Australia and David Yates from Corrs Chambers Westgarth.
You can stream the Forum on the ABC website, or download here.

Instagram’s privacy updates for kids are positive. But plans for an under-13s app means profits still take precedence

Shutterstock
By Tama Leaver, Curtin University
Facebook recently announced significant changes to Instagram for users aged under 16. New accounts will be private by default, and advertisers will be limited in how they can reach young people.
The new changes are long overdue and welcome. But Facebook’s commitment to childrens’ safety is still in question as it continues to develop a separate version of Instagram for kids aged under 13.
The company received significant backlash after the initial announcement in May. In fact, more than 40 US Attorneys General who usually support big tech banded together to ask Facebook to stop building the under-13s version of Instagram, citing privacy and health concerns.
Privacy and advertising
Online default settings matter. They set expectations for how we should behave online, and many of us will never shift away from this by changing our default settings.
Adult accounts on Instagram are public by default. Facebook’s shift to making under-16 accounts private by default means these users will need to actively change their settings if they want a public profile. Existing under-16 users with public accounts will also get a prompt asking if they want to make their account private.
These changes normalise privacy and will encourage young users to focus their interactions more on their circles of friends and followers they approve. Such a change could go a long way in helping young people navigate online privacy.
Facebook has also limited the ways in which advertisers can target Instagram users under age 18 (or older in some countries). Instead of targeting specific users based on their interests gleaned via data collection, advertisers can now only broadly reach young people by focusing ads in terms of age, gender and location.
This change follows recently publicised research that showed Facebook was allowing advertisers to target young users with risky interests “” such as smoking, vaping, alcohol, gambling and extreme weight loss “” with age-inappropriate ads.
This is particularly worrying, given Facebook’s admission there is “no foolproof way to stop people from misrepresenting their age” when joining Instagram or Facebook. The apps ask for date of birth during sign-up, but have no way of verifying responses. Any child who knows basic arithmetic can work out how to bypass this gateway.
Of course, Facebook’s new changes do not stop Facebook itself from collecting young users’ data. And when an Instagram user becomes a legal adult, all of their data collected up to that point will then likely inform an incredibly detailed profile which will be available to facilitate Facebook’s main business model: extremely targeted advertising.
Deploying Instagram’s top dad
Facebook has been highly strategic in how it released news of its recent changes for young Instagram users. In contrast with Facebook’s chief executive Mark Zuckerberg, Instagram’s head Adam Mosseri has turned his status as a parent into a significant element of his public persona.
Since Mosseri took over after Instagram’s creators left Facebook in 2018, his profile has consistently emphasised he has three young sons, his curated Instagram stories include #dadlife and Lego, and he often signs off Q&A sessions on Instagram by mentioning he needs to spend time with his kids.
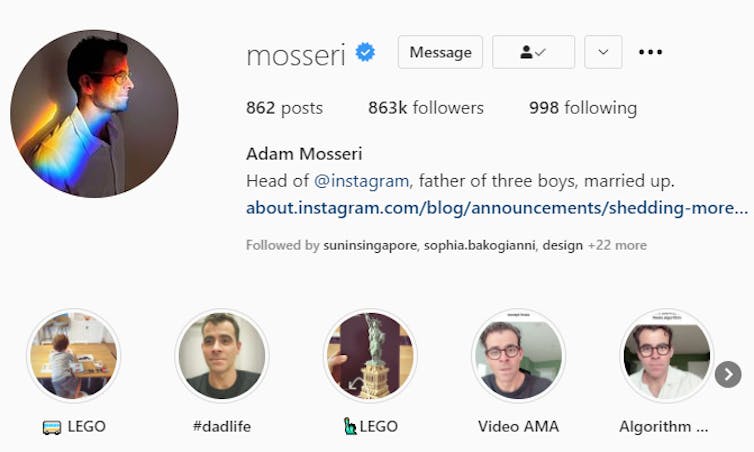
When Mosseri posted about the changes for under-16 Instagram users, he carefully framed the news as coming from a parent first, and the head of one of the world’s largest social platforms second. Similar to many influencers, Mosseri knows how to position himself as relatable and authentic.
Age verification and ‘potentially suspicious’ adults
In a paired announcement on July 27, Facebook’s vice-president of youth products Pavni Diwanji announced Facebook and Instagram would be doing more to ensure under-13s could not access the services.
Diwanji said Facebook was using artificial intelligence algorithms to stop “adults that have shown potentially suspicious behavior” from being able to view posts from young people’s accounts, or the accounts themselves. But Facebook has not offered an explanation as to how a user might be found to be “suspicious”.
Diwanji notes the company is “building similar technology to find and remove accounts belonging to people under the age of 13”. But this technology isn’t being used yet.
It’s reasonable to infer Facebook probably won’t actively remove under-13s from either Instagram or Facebook until the new Instagram For Kids app is launched “” ensuring those young customers aren’t lost to Facebook altogether.
Despite public backlash, Diwanji’s post confirmed Facebook is indeed still building “a new Instagram experience for tweens”. As I’ve argued in the past, an Instagram for Kids “” much like Facebook’s Messenger for Kids before it “” would be less about providing a gated playground for children and more about getting children familiar and comfortable with Facebook’s family of apps, in the hope they’ll stay on them for life.
A Facebook spokesperson told The Conversation that a feature introduced in March prevents users registered as adults from sending direct messages to users registered as teens who are not following them.
“This feature relies on our work to predict peoples’ ages using machine learning technology, and the age people give us when they sign up,” the spokesperson said.
They said “suspicious accounts will no longer see young people in ‘Accounts Suggested for You’, and if they do find their profiles by searching for them directly, they won’t be able to follow them”.
Resources for parents and teens
For parents and teen Instagram users, the recent changes to the platform are a useful prompt to begin or to revisit conversations about privacy and safety on social media.
Instagram does provide some useful resources for parents to help guide these conversations, including a bespoke Australian version of their Parent’s Guide to Instagram created in partnership with ReachOut. There are many other online resources, too, such as CommonSense Media’s Parents’ Ultimate Guide to Instagram.
Regarding Instagram for Kids, a Facebook spokesperson told The Conversation the company hoped to “create something that’s really fun and educational, with family friendly safety features”.
But the fact that this app is still planned means Facebook can’t accept the most straightforward way of keeping young children safe: keeping them off Facebook and Instagram altogether.
![]()
Tama Leaver, Professor of Internet Studies, Curtin University
This article is republished from The Conversation under a Creative Commons license. Read the original article.
The Future Of Children’s Online Privacy
I was delighted to join Dr Anna Bunn, Deputy Head of Curtin Law School, and the Future Of team for a podcast interview all about Children’s Online Privacy.
The half hour podcast is online here in various formats, including shownotes, or embedded in this post:
We discuss:
What’s the impact of parents sharing content of their children online? And what rights do children have in this space?
In this episode, Jessica is joined by Dr Anna Bunn, Deputy Head of Curtin Law School and Tama Leaver, Professor of Internet Studies at Curtin University to discuss “sharenting” – the growing practice of parents sharing images and data of their children online. The three examine the social, legal and developmental impacts a life-long digital footprint can have on a child.
- What is the impact of sharing child-related content on our kids? [04:08]
- What type of tools and legal protections would you like to see in the future to protect children? [16:30]
- At what age can a child give consent to share content [18:25]
- What about the right to be forgotten [21:11]
- What’s best practice for sharing child-related content online? [26:01]
Happy birthday Instagram! 5 ways doing it for the ‘gram has changed us
Tama Leaver, Curtin University; Crystal Abidin, Curtin University, and Tim Highfield, University of Sheffield

6 October 2020 marks Instagram’s tenth birthday. Having amassed more than a billion active users worldwide, the app has changed radically in that decade. And it has changed us.
1. Instagram’s evolution
When it was launched on October 6, 2010 by Kevin Systrom and Mike Krieger, Instagram was an iPhone-only app. The user could take photos (and only take photos “” the app could not load existing images from the phone’s gallery) within a square frame. These could be shared, with an enhancing filter if desired. Other users could comment or like the images. That was it.
As we chronicle in our book, the platform has grown rapidly and been at the forefront of an increasingly visual social media landscape.
In 2012, Facebook purchased Instagram for a deal worth a $US1 billion (A$1.4 billion), which in retrospect probably seems cheap. Instagram is now one of the most profitable jewels in the Facebook crown.
Instagram has integrated new features over time, but it did not invent all of them.
Instagram Stories, with more than half a billion daily users, was shamelessly borrowed from Snapchat in 2016. It allowed users to post 10-second content bites which disappear after 24 hours. The rivers of casual and intimate content (later integrated into Facebook) are widely considered to have revitalised the app.
Similarly, IGTV is Instagram’s answer to YouTube’s longer-form video. And if the recently-released Reels isn’t a TikTok clone, we’re not sure what else it could be.
Read more: Facebook is merging Messenger and Instagram chat features. It’s for Zuckerberg’s benefit, not yours
2. Under the influencers
Instagram is largely responsible for the rapid professionalisation of the influencer industry. Insiders estimated the influencer industry would grow to US$9.7 billion (A$13.5 billion) in 2020, though COVID-19 has since taken a toll on this as with other sectors.
As early as in 2011, professional lifestyle bloggers throughout Southeast Asia were moving to Instagram, turning it into a brimming marketplace. They sold ad space via post captions and monetised selfies through sponsored products. Such vernacular commerce pre-dates Instagram’s Paid Partnership feature, which launched in late-2017.

The use of images as a primary mode of communication, as opposed to the text-based modes of the blogging era, facilitated an explosion of aspiring influencers. The threshold for turning oneself into an online brand was dramatically lowered.
Instagrammers relied more on photography and their looks “” enhanced by filters and editing built into the platform.
Soon, the “extremely professional and polished, the pretty, pristine, and picturesque” started to become boring. Finstagrams (“fake Instagram“) and secondary accounts proliferated and allowed influencers to display behind-the-scenes snippets and authenticity through calculated performances of amateurism.
3. Instabusiness as usual
As influencers commercialised Instagram captions and photos, those who had owned online shops turned hashtag streams into advertorial campaigns. They relied on the labour of followers to publicise their wares and amplify their reach.
Bigger businesses followed suit and so did advice from marketing experts for how best to “optimise” engagement.
In mid-2016, Instagram belatedly launched business accounts and tools, allowing companies easy access to back-end analytics. The introduction of the “swipeable carousel” of story content in early 2017 further expanded commercial opportunities for businesses by multiplying ad space per Instagram post. This year, in the tradition of Instagram corporatising user innovations, it announced Instagram Shops would allow businesses to sell products directly via a digital storefront. Users had previously done this via links.

Read more: Friday essay: Twitter and the way of the hashtag
4. Sharenting
Instagram isn’t just where we tell the visual story of ourselves, but also where we co-create each other’s stories. Nowhere is this more evident than the way parents “sharent“, posting their children’s daily lives and milestones.
Many children’s Instagram presence begins before they are even born. Sharing ultrasound photos has become a standard way to announce a pregnancy. Over 1.5 million public Instagram posts are tagged #genderreveal.
Sharenting raises privacy questions: who owns a child’s image? Can children withdraw publishing permission later?
Sharenting entails handing over children’s data to Facebook as part of the larger realm of surveillance capitalism. A saying that emerged around the same time as Instagram was born still rings true: “When something online is free, you’re not the customer, you’re the product”. We pay for Instagram’s “free” platform with our user data and our children’s data, too, when we share photos of them.

Read more: The real problem with posting about your kids online
5. Seeing through the frame
The apparent “Instagrammability” of a meal, a place, or an experience has seen the rise of numerous visual trends and tropes.
Short-lived Instagram Stories and disappearing Direct Messages add more spaces to express more things without the threat of permanence.
Read more: Friday essay: seeing the news up close, one devastating post at a time
The events of 2020 have shown our ways of seeing on Instagram reveal the possibilities and pitfalls of social media.
In June racial justice activism on #BlackoutTuesday, while extremely popular, also had the effect of swamping the #BlackLivesMatter hashtag with black squares.
Instagram is rife with disinformation and conspiracy theories which hijack the look and feel of authoritive content. The template of popular Instagram content can see familiar aesthetics weaponised to spread misinformation.
Ultimately, the last decade has seen Instagram become one of the main lenses through which we see the world, personally and politically. Users communicate and frame the lives they share with family, friends and the wider world.
Read more: #travelgram: live tourist snaps have turned solo adventures into social occasions
Tama Leaver, Associate Professor in Internet Studies, Curtin University; Crystal Abidin, Senior Research Fellow & ARC DECRA, Internet Studies, Curtin University, Curtin University, and Tim Highfield, Lecturer in Digital Media and Society, University of Sheffield
This article is republished from The Conversation under a Creative Commons license. Read the original article.
Reflections and Resources from the 2017 Digitising Early Childhood Conference
Last week’s Digitising Early Childhood conference here in Perth was a fantastic event which brought together so many engaging and provocative scholars in a supportive and policy/action-orientated environment (which I suppose I should call ‘engagement and impact’-orientated in Australia right now). For a pretty well document overview of the conference itself, you can see the quite substantial tweets collected via the #digikids17 hashtag on Twitter, which I’d really encourage you to look over. My head is still buzzing, so instead to trying to synthesise everyone else’s amazing work, I’m just going to quickly point to the material that arose my three different talks in case anyone wishes to delve further.
First up, here are the slides for my keynote ‘Turning Babies into Big Data””And How to Stop It‘:
 If you’d like to hear the talk that goes with the slides, there’s an audio recording you can download here. (I think these were filmed, so if a link becomes available at some point, I’ll update and post it here.) There was a great response to my talk, which was humbling and gratifying at the same time. There was also quite a lot of press interest, too, so here’s the best pieces that are available online (and may prove a more accessible overview of some of the issues I explored):
If you’d like to hear the talk that goes with the slides, there’s an audio recording you can download here. (I think these were filmed, so if a link becomes available at some point, I’ll update and post it here.) There was a great response to my talk, which was humbling and gratifying at the same time. There was also quite a lot of press interest, too, so here’s the best pieces that are available online (and may prove a more accessible overview of some of the issues I explored):
- Rebecca Turner’s ABC article ‘Owlet Smark Sock prompts warning for parents, fears over babies’ sensitive health data‘;
- Leon Compton’s interview on ABC Radio Tasmania ‘Social media and parenting: the do’s and don’ts’ (audio);
- Brigid O’Connell’s Herald Sun story, Parents may be unwittingly turning babies into big data (paywalled); and
- Cathy O’Leary’s story in The Western Australian, Parents airing kids’ lives on social media.
While our argument is still being polished, the slides for this version of Crystal Abidin and my paper From YouTube to TV, and back again: Viral video child stars and media flows in the era of social media are also available:
This paper began as a discussion after our piece about Daddy O Five in The Conversation and where the complicated questions about children in media first became prominent. Crystal wasn’t able to be there in person, but did a fantastic Snapchat-recorded 5-minute intro, while I brought home the rest of the argument live. Crystal has a great background page on her website, linking this to her previous work in the area. There was also press interest in this talk, and the best piece to listen to (and hear Crystal and I in dialogue, even though this was recorded at different times, on different continents!):
- Brett Worthington’s Life Matters segment on Radio National, How social media videos turn children into viral sensations (audio)
Finally, as part of the Higher Degree by Research and Early Career Researcher Day which ended the conference, I presented a slightly updated version of my workshop ‘Developing a scholarly web presence & using social media for research networking’:
Overall, it was a very busy, but very rewarding conference, with new friends made, brilliant new scholarship to digest, and surely some exciting new collaborations begun!

[Photo of the Digitising Early Childhood Conference Keynote Speakers]

Tama Leaver dot Net by Tama Leaver is licensed under a Creative Commons Attribution-NonCommercial-ShareAlike 4.0 International License.